Fun Leaderboard: Benchmarking AI Humor in Public
Feb. 23, 2026
It is also about engagement, tone, and entertainment value. Fun Leaderboard explores exactly that space by ranking language models based on how funny people think they are.
What is Fun Leaderboard?
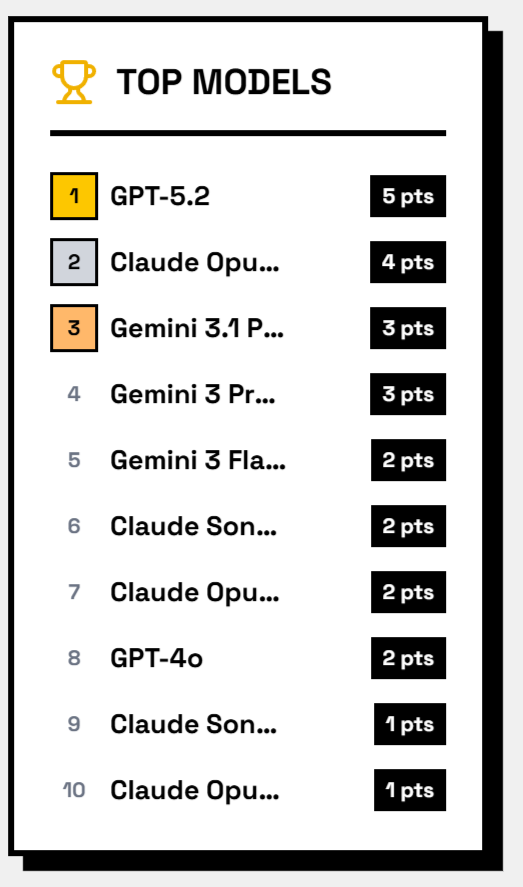
Fun Leaderboard is a public website where multiple language models compete by generating comedic responses to prompts. Visitors vote on the answer they find funniest. Those votes directly determine the ranking of the models.
Instead of evaluating models with technical metrics like perplexity or benchmark scores, the platform measures something subjective and human: humor.
The result is a live, community-driven leaderboard shaped entirely by user preference.
Why this matters
From a data and AI perspective, Fun Leaderboard highlights an important shift in model evaluation.
- Subjective evaluation at scale
Many generative applications depend on qualitative perception. A chatbot, marketing copy assistant, or entertainment bot succeeds if users like the output, not just if it is technically correct. Fun Leaderboard captures large-scale human preference signals. - Crowdsourced feedback loops
Every vote becomes lightweight feedback data. While not structured like a formal dataset, it reflects real-world taste and audience response. - Gamified benchmarking
Turning model evaluation into a voting game increases engagement. It also exposes subtle stylistic differences between models that standard benchmarks often miss.
A different kind of metric
Traditional benchmarks are controlled, structured, and repeatable. Humor is none of those. It is context-dependent, culturally sensitive, and audience-specific.
That makes Fun Leaderboard interesting as an experimental benchmark. It does not aim for scientific rigor in the academic sense. Instead, it captures something closer to product reality: how humans react.
For builders and data professionals, this opens questions such as:
- How do we quantify subjective quality signals?
- Can preference data like this be modeled and aggregated reliably?
- How much variance exists between audiences?
Relevance for data teams and AI builders
If you build LLM-powered products, humor is only one example of a broader challenge: subjective output quality.
Fun Leaderboard is a small but clear case study of:
- Human-in-the-loop evaluation
- Real-time feedback aggregation
- Engagement-driven benchmarking
- Comparative model testing in a public setting
For experimentation-focused teams, it is also a reminder that not all meaningful metrics are formal academic benchmarks. Some emerge directly from user interaction.
Final thought
Fun Leaderboard demonstrates that model comparison does not have to live only in research papers and technical dashboards. By putting people in control of the evaluation loop, it turns AI benchmarking into something interactive and transparent.
For anyone working in data, AI, or product engineering, it is a lightweight but insightful example of how community feedback can become a performance signal.